👀 Quick Tour#
Once installed, you are ready to use  for building MGT datasets either using the
for building MGT datasets either using the text_machina/src/cli.py or programmatically.
📟 Using the CLI#
The first step is to define a YAML configuration file or a directory tree containing YAML files. Read the etc/examples/learning files to learn how to define configuration using different providers and extractors for different tasks. Take a look to etc/examples/use_cases to see configurations for specific use cases.
Then, we can call the explore and generate endpoints of ‘s CLI. The explore endpoint allows to inspect a small generated dataset using an specific configuration through an interactive interface. For instance, let’s suppose we want to check how an MGT detection dataset generated using XSum news articles and gpt-3.5-turbo-instruct looks like, and compute some metrics:
text-machina explore --config-path etc/examples/xsum_gpt-3-5-turbo-instruct_openai.yaml \
--task-type detection \
--metrics-path etc/metrics.yaml \
--max-generations 10
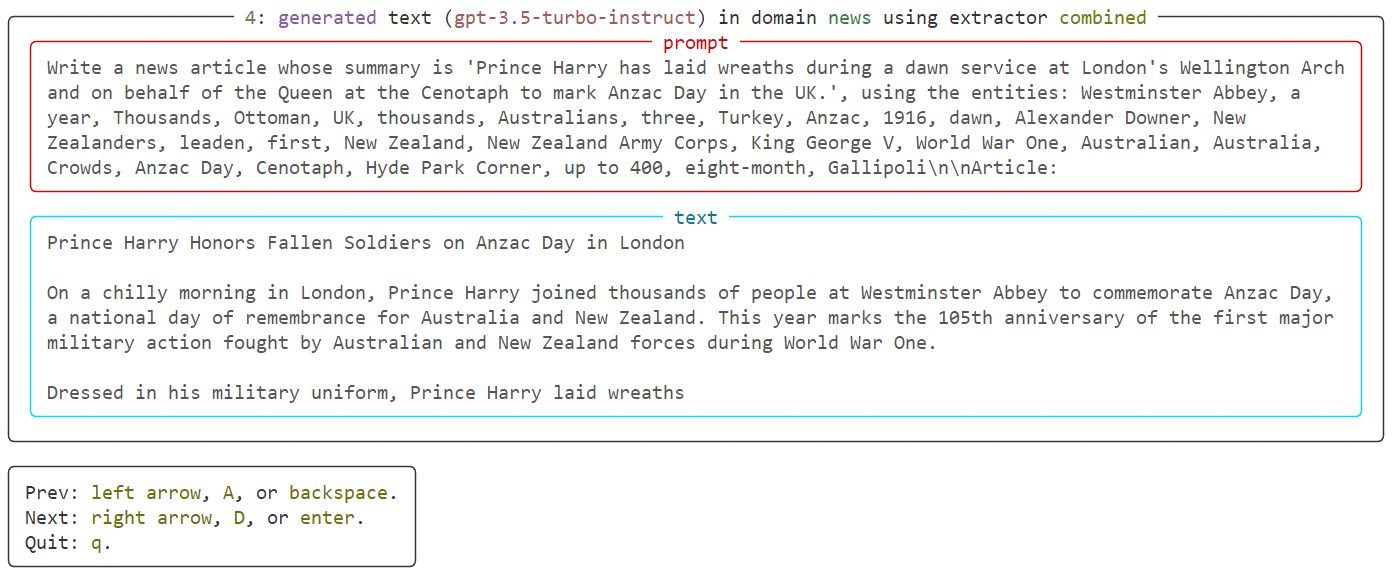
Great! Our dataset seems to look great, no artifacts, no biases, and high-quality text using this configuration. Let’s now generate a whole dataset for MGT detection using that config file. The generate endpoint allows you to do that:
text-machina generate --config-path etc/examples/xsum_gpt-3-5-turbo-instruct_openai.yaml \
--task-type detection
A run name will be assigned to your execution and will cache results behind the scenes. If your run is interrupted at any point, you can use --run-name <run-name> to recover the progress and continue generating your dataset.
👩💻 Programmatically#
You can also use programmatically. To do that, instantiate a dataset generator by calling get_generator with a Config object, and run its generate method. The Config object must contain the input, model, and generation configs, together with the task type for which the MGT dataset will be generated. Let’s replicate the previous experiment programmatically:
from text_machina import get_generator
from text_machina import Config, InputConfig, ModelConfig
input_config = InputConfig(
domain="news",
language="en",
quantity=10,
random_sample_human=True,
dataset="xsum",
dataset_text_column="document",
dataset_params={"split": "test"},
template=(
"Write a news article whose summary is '{summary}'"
"using the entities: {entities}\n\nArticle:"
),
extractor="combined",
extractors_list=["auxiliary.Auxiliary", "entity_list.EntityList"],
max_input_tokens=256,
)
model_config = ModelConfig(
provider="openai",
model_name="gpt-3.5-turbo-instruct",
api_type="COMPLETION",
threads=8,
max_retries=5,
timeout=20,
)
generation_config = {"temperature": 0.7, "presence_penalty": 1.0}
config = Config(
input=input_config,
model=model_config,
generation=generation_config,
task_type="detection",
)
generator = get_generator(config)
dataset = generator.generate()